
En la actualidad, la comunidad va ejecutando cada vez más aplicaciones en contenedores, porque ejecutar aplicaciones, bases de datos u otras herramientas en contenedores Docker es muy atractivo. Es un hecho que esta metodología aporta aislamiento, fácil configuración o seguridad, entre otras prestaciones. Sin embargo, a veces, la depuración, el acceso o, en general, la interacción con los contenedores puede …

En la actualidad, la comunidad va ejecutando cada vez más aplicaciones en contenedores, porque ejecutar aplicaciones, bases de datos u otras herramientas en contenedores Docker es muy atractivo. Es un hecho que esta metodología aporta aislamiento, fácil configuración o seguridad, entre otras prestaciones. Sin embargo, a veces, la depuración, el acceso o, en general, la interacción con los contenedores puede resultar bastante incómoda. Esto incluye el acceso, la modificación o la consulta de las bases de datos. Así que, en el siguiente post, proporcionamos una serie de comandos que pueden ayudar considerablemente cuando se hace una operación simple – o no tan simple – con un servidor de base de datos.
Iniciar sesión en PSQL
Antes de poder iniciar la sesión en nuestra base de datos, tendremos que desplegar nuestro contenedor de Postgres. Lo más básico que siempre se ha de hacer, para interactuar con el servidor de base de datos, es conectarse a la base de datos en sí (usando PSQL):
![]()
Así que, como ejemplo, el contenedor Docker llamado db, el usuario por defecto postgres y el nombre de la base de datos neodata, tendríamos la siguiente línea de comandos:
![]()
El comando -it, nos permitirá interactuar con el contenedor, por lo que es importante incluirlo.
Ejecutar el comando contra la base de datos
Es interesante poder iniciar sesión, pero lógicamente se necesita poder ejecutar más comandos. Se puede, por tanto, ejecutar cualquier comando que se necesite, aunque, a menudo, es más conveniente hacerlo de una sola vez, especialmente si se quiere ejecutar una consulta únicamente:
![]()
Por tanto, si quisiéramos listar todas las tablas de la base de datos usando los mismos parámetros que en el ejemplo anterior:
![]()
Aquí, \l lista todas las tablas de la base de datos actual. Aparte de los comandos de psql se puede ejecutar cualquier consulta SQL de esta manera:
![]()
En este ejemplo, se ha incluido un comando para listar todos los elementos de la tabla devops.
Hacer una copia de seguridad de los datos
De vez en cuando es necesario realizar copias de seguridad de los datos, o de todo el esquema de la base de datos; a veces sólo como una “póliza de seguro” y otras veces para poder hacer cambios imprudentes y restaurarlo todo después. La forma de hacer dicha copia de seguridad sería la siguiente:
![]()
En este ejemplo, se ha realizado con la herramienta / utilidad pg_dump, que nos permite extraer bases de datos PostgreSQL. Se utilizan los flags –column-inserts y –data-only para obtener sólo filas de tablas, pero a menudo todo lo que se necesita es un esquema, para eso se puede usar el flag -s. Siguiendo con los ejemplos anteriores el comando sería el siguiente:
![]()
Como resultado tendremos un archivo backup.sql en la ruta donde se ha ejecutado el comando de la base de datos neodata.
Ejecutar archivos SQL completos
En algunas ocasiones, se necesita importar datos a la base de datos existente con suficientes datos para hacer pruebas o, simplemente, es más fácil usar los datos del archivo y luego copiarlos y pegarlos en el comando de arriba:
![]()
![]()
Aquí, primero necesitamos copiar el archivo en sí mismo en el contenedor en ejecución y luego ejecutarlo usando el flag -f.
Prepoblación de la base de datos en el inicio
El ejemplo anterior era lo suficientemente bueno si necesitas ejecutarlo de vez en cuando, pero puede resultar molesto si tienes que hacerlo cada vez que inicias la base de datos. Por lo tanto, en caso de que se decida que es mejor llenar la base de datos desde el principio, aquí se propone una solución. Sólo requiere un poco más de trabajo:
Necesitaremos los siguientes archivos:
- Dockerfile – Dockerfile con la imagen de Postgres.
- create_db.sh – Script que crea la base de datos, el esquema y lo rellena.
- schema.sql – Archivo SQL que contiene el esquema de la base de datos.
- data.sql – Archivo SQL que contiene los datos utilizados para llenar la base de datos.
- .env – Archivo con variables de entorno, para hacernos la vida más fácil
Primero, el Dockerfile:

Es un Dockerfile bastante simple. Todo lo que se necesita hacer aquí es copiar nuestro script y el esquema/datos en la imagen para que puedan estar en el inicio de la ejecución. Puede que alguien se pregunta por qué no hay ningún ENTRYPOINT o COMMAND, ¿cómo lo ejecutamos en el arranque? – la respuesta es que la imagen base de postgres se ejecuta al iniciar cualquier script presente en el directorio docker-entrypoint-initdb.d, así que todo lo que necesitamos hacer es copiar nuestro script a este directorio y PostgreSQL se encarga de ello.
Pero, ¿qué hay en el script (create_db.sh)?
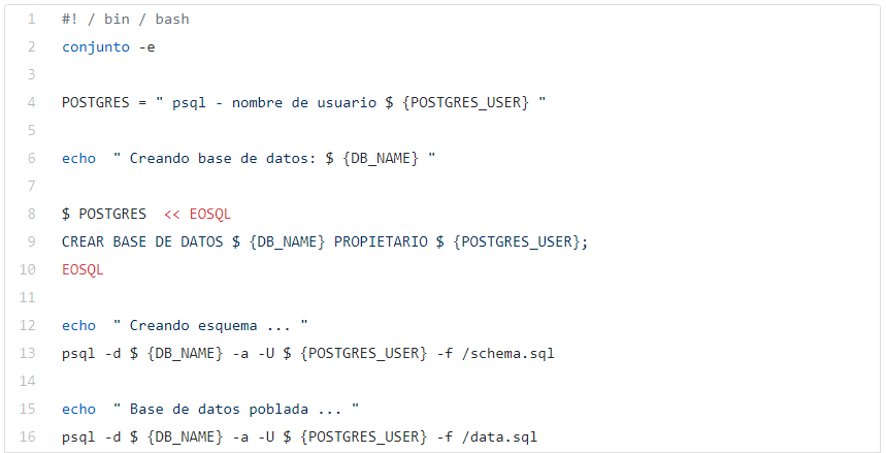
El script de arranque, primero, inicia sesión en psql con el nombre de usuario especificado (POSTGRES_USER), luego crea su base de datos (DB_NAME). A continuación, crea el esquema de la base de datos utilizando el archivo que hemos copiado en la imagen (schema.sql) y, finalmente, llena la base de datos con datos proporcionados (data.sql). Todas las variables aquí provienen del archivo .env mencionado anteriormente, lo que hace muy fácil cambiar el nombre de la base de datos o el nombre de usuario en cualquier momento sin modificar el propio script.
¿Y desplegar con docker-Compose?
En mi experiencia, la mayoría de las veces termino levantando la base de datos en conjunto con la aplicación que la está usando y la forma más simple de hacerlo es con docker-compose. Normalmente es preferible referirse a docker-compose por el nombre del servicio, en lugar de por el nombre del contenedor, ya que puede ser (o no) el mismo despliegue. En caso de que no sea lo mismo, puedes seguir el comando:
![]()
La única diferencia real aquí con los ejemplos anteriores es la parte de docker-compose, que busca información del servicio especificado con el comando ps. El flag -q hace que sólo se muestren los ID de los contenedores, en lugar la información estándar, que es todo lo que necesitamos en este caso.
Conclusión
Con este pequeño post se ha pretendido ayudar a ver la utilidad de desplegar una base de datos con Docker. Existe mucha controversia sobre este tema, ya que existen detractores a la hora de desplegar bases de datos “dockerizadas”, en vez de instalarlas directamente en la capa de sistema operativo. Sin embargo, se puede observar la sencillez y, sobre todo, la velocidad en el despliegue, ya que no tenemos que provisionar un sistema operativo y la consiguiente pérdida de tiempo que su pone instalar drivers y utilidades, ya que todo está paquetizado y listo para desplegar en nuestra imagen de Docker.
News