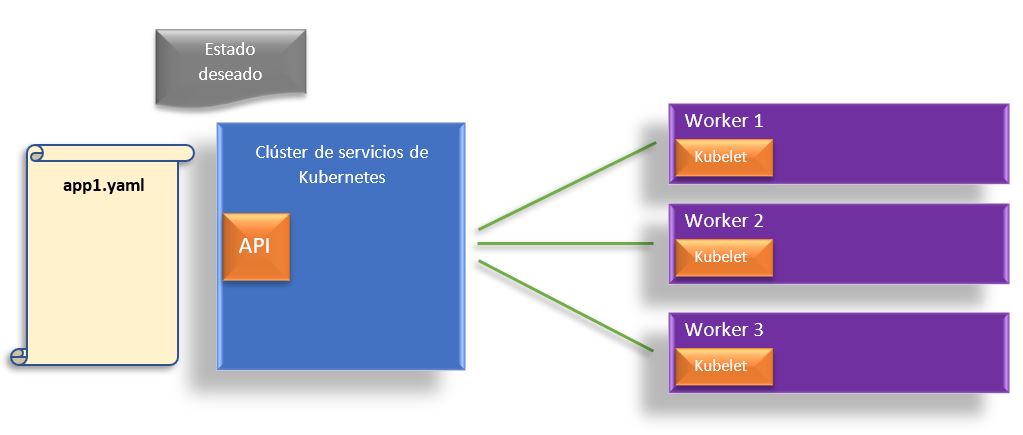
El segundo bloque de la arquitectura del sistema se llama Worker. Pero, ¿Qué es un worker? Un worker es básicamente un host de contenedores. Lo único que tiene un worker o el host de contenedores en un entorno kubernetes, es que tiene un proceso llamado Kubelet en ejecución, que es responsable de comunicarse con el clúster de servicios Kubernetes.
Por tanto, todos esos workers y el clúster de servicios de Kubernetes, es lo que componen un Cluster de Kubernetes.
Llegados a este punto, se va a poner todo en contexto y a plantear un caso de uso. En este caso lo que queremos hacer es nutrir nuestro clúster de servicios con una configuración. Así que el estado deseado, por así decirlo, se va a definir en un archivo de implementación de tipo YAML que se llamará “app1.yaml”.
Dentro de esto puede haber un montón de información y configuración que vamos a omitir en gran medida, aunque hablaremos de dos piezas fundamentales, la primera de las cuales, en este archivo de implementación, es una configuración de un Pod. Un pod es la unidad atómica de implementación en el modelo de objetos de Kubernetes. Esto significa que, en un pod, se encontrarán contenedores (puede tener uno o más) en ejecución. Para poder ejecutar ese pod necesitamos especificar algún tipo de imagen (archivo binario) de contenedor, o tal vez, dos imágenes de contenedor y, más adelante, habrá otros elementos para definir como, por ejemplo, los puertos dónde se ejecutan los servicios. Así, el otro elemento adicional es que se va a especificar, en este caso, el número de réplicas, o en otras palabras, cuántos de estos pods deben ejecutarse aquí.
Para este caso, el número de réplicas para el pod1 se va a fijar en 3. Es decir, tendremos 3 pods1 idénticos en ejecución en los workers antes descritos.
A continuación, se va a añadir un nuevo pod (pod2 por ejemplo) con una única imagen, en este caso, y con el número de replicas igual a 2.
El próximo paso a dar es coger este archivo YAML con la configuración y dársela a la API del clúster de Kubernetes y lo que la API hará es programar, en los Workers, el despliegue del estado deseado que se ha definido en el archivo YAML.
El clúster de servicios será el encargado de mantener la configuración del archivo YAML, en este estado deseado, en los distintos workers donde se ha realizado el despliegue. Por tanto, simulando un nuevo escenario dentro del caso de uso, ¿Qué ocurriría si uno de los workers se vuelve inaccesible?
Nos encontramos con que la situación actual no concuerda con el estado deseado definido en el archivo YAML y el clúster de servicios se comunicará con el proceso Kubelet de uno de los workers y desplegará el pod1 que tenía el worker2 en otro de los workers (en este caso al worker 1), por lo que se conseguirá el estado deseado de nuevo, con el número de pods y sus réplicas definidos anteriormente.
Aquí termina la pequeña introducción al concepto de Kubernetes y un caso de uso con sus problemas y soluciones. Si necesitas más información no dudes en contactar con nosotros.